
Pensando inicialmente como uma prova de conceito, a ideia de usar Github Issues em comentários de blogs vem ganhando força, a exemplo das ferramentas utterance, gitalk, gitcomment, etc.
É simplesmente genial, pois você não precisa de servidor para executar um sistema de comentários, além de que eles são guardados em um repositório do próprio github (onde geralmente se guarda os arquivos de um site estático). Porém, há limitações inconvenientes nas soluções citadas, por isso demonstro neste post como eu as contornei, além da proposta de ideias para melhoramento.
Github issues como comentários em blogs
Comentários sempre são uma opção interessante em blogs, pois captam a opinião de um leitor mais atento, que quer se expressar por meio de uma breve, ou não, resposta à opinião de quem escreveu um artigo. Há quem diga que blogs sem comentários não são realmente blogs.
Porém, há hoje uma grande oferta de sistemas de comentários para sites, que vão desde as opções auto hospedadas, aos serviços com planos de assinatura (o que às vezes inclui planos gratuitos) para mantê-lo presente no seu espaço virtual.
Como falado no início, a ideia de usar Github issues - que originalmente foram projetadas para serem um canal público de perguntas de usuários a um repositório dentro da plataforma - como um artifício para permitir comentários em blogs remonta a 2011, com um post de Ivan Zuzak. Lá ele propôs alguns tópicos de interesse para suas motivações. Um deles foi: deve ser fácil de usar pelos leitores do blog.
Comparando de lá pra cá a maioria das postagens sobre o tema “comentários em blogs com github issues” - como visto aqui, aqui aqui, aqui e aqui -, percebi a seguinte máxima dos proprietários dos sites que implantam esses tipos de mecanismo: “Considero que a maioria dos meus leitores têm conta no Github, então o login na plataforma não será problema” ou “que legal, levei um susto pela facilidade de uso!”. Mas há aí uma lacuna que realmente exclui qualquer usuário que não tenha uma conta nesse serviço ou até um conhecimento para tal, muitas vezes não sabe nem o que significa Github (para muitos, ‘repositório de código’ é um termo até incompreendido).
Então, pensei no dilema porvir: criar um blog de tecnologia, e implicitamente considerar que os meus leitores têm conta no Github ou criar um blog sobre outros assuntos, implantar um sistema que use issues como comentários e obrigar os meus usuários a criarem conta no Github, se quiserem comentar em uma postagem. Isso parecia contrassenso. Não poderia obrigar nenhum usuário a se cadastrar em um serviço, que ele já não tivesse acesso regular, para poder comentar. Por isso, nesse meio tempo estava utilizando o CommentBox, pois me dava a opção de cadastro por e-mail e através de redes sociais da grande mídia. Eu só o tinha escolhido por suportar um plano gratuito de até 100 comentários por mês (para um blog pessoal de um quase desconhecido é mais do que o suficiente, rsrs) e ter uma clara e não tão invasiva política de privacidade ao usuário que faz login, além de sem ads nem rastreamento.
Graças a Santa Internet, encontrei outras postagens relatando o mesmo incômodo que eu estava sentindo, quanto à impossibilidade de comentários anônimos em sistemas que usam issues no github. De rombo, além de propor um artifício sobre a possibilidade de postagens anônimas, o usuário chinês bigbyto relatou em um artigo em seu blog pessoal algumas modificações no sistema Gitalk que ele tinha feito, como a retirada de segredos adicionados no frontend do site. Mas isso tinha um preço: um servidor de backend agindo paralelamente. Bem, voltarei a isso após o próximo tópico.
Breve estudo sobre o impacto dos comentários anônimos
Há uma literatura científica considerável sobre os impactos de comentadores anônimos em diferentes tipos de sites, como jornalísticos (1 e 2), plataformas de aprendizado e fóruns na internet. Segundo esses trabalhos:
-
Na área da educação e aprendizado colaborativo: Usar tarefas de redação online usando pseudônimos pode ser uma estratégia de ensino eficaz que induz uma maior participação online, especialmente entre os alunos que hesitam em participar em um ambiente de sala de aula tradicional.
-
Na área jornalística: 1- Muitos jornalistas e observadores da indústria apontaram o anonimato como uma razão aparentemente direta para os comentários ofensivos, apesar da escassez de evidências empíricas de suporte. 2 - Comentaristas anônimos são significativamente mais propensos a registrar sua opinião com comentários rudes do que os não anônimos, em sites jornalísticos envolvendo temas polêmicos, como discussão sobre gênero e imigração. 3 - Com relação a sites com conteúdos não polêmicos e menos controversos (ou politicamente não tendenciosos), é sugerido que exigir a identificação dos comentadores não mudaria as percepções dos leitores de notícias online sobre os comentários e não afetaria sua confiança nas informações desses comentários.
-
Uma revisão amplamente aceita para a teoria da presença social aborda como as interfaces virtuais e o design afetam a presença social, vagamente definida como a “sensação de estar com o outro”. Ela é utilizada por pesquisadores do campo da interação humano-computador para avaliar como as diferenças nas interfaces afetam o sentido de presença social. Isso sugere que pessoas que não estão fisicamente presentes podem parecer estar presentes, dependendo do grau de presença. Ou seja, quanto maior a presença social, mais provável que olhemos os outros debatedores/comentadores de maneira mais subjetiva e reajamos a eles com mais civilidade. Consequentemente, à medida que a presença social diminui, há maior probabilidade para incidência de mensagens menos pessoais ou menos amigáveis.
-
Leitores de conteúdo reconhecem a natureza mordaz dos comentários online, mas preferem permitir comentários anônimos e vê-los como fortalecedores e libertadores (3 e 4). Os usuários também abraçam o anonimato como uma proteção contra a perda de privacidade e a “difamação da dissidência”.
Baseado nos pontos supracitados, tendo em vista o conteúdo diverso produzido no meu blog e os artifícios técnicos que mantenho em constante mudança, a fim de representar tanto minha forma de expressão quanto a tentativa de aproximação do leitor para comigo (e o que pode afetar positivamente em sua presença social), bem como a minha vontade de transformar a web em um espaço mais democrático, a partir do uso de ferramentas que promovam esse uso mais simples e - aparentemente - espontâneo da blogosfera, decidi acolher os comentadores anônimos.
Definitivamente não vou dar um desdobro qualquer na tentativa de ofuscar uma impossibilidade técnica, preguiça ou de simplesmente vergonha de não ter o conhecimento para tal. Acho que tudo na vida é aprendizado e todos nós deveríamos entender até onde podemos chegar naquele momento e qual a direção querer seguir, mesmo usando, mas não gostando da solução atual. Percebi que o IanVoyager, nesta postagem, e continuando com meu questionamento nos comentários do artigo, ainda almeja a função dos comentários anônimos.
Retomando…
Pois bem, eu testei a solução customizada do Bigbyto. Rodei um código backend que ele mesmo tinha feito e hospedado aqui, tentei rodar no Cloudflare workers, porém ele relatou que só foi usado no Vercel. Então, criei uma conta no serviço e subi a aplicação. Depois de idas e vindas eu tinha conseguido replicar seu experimento, meio no escuro, já que ele mesmo relatou que o código estava muito “plástico” e não documentado (apesar de ter esse plano no futuro).
Depois de conseguir rodar, fiquei pensando que ainda não poderia usá-lo em produção, pois o meu conhecimento estava muito cru com relação ao sistema, e tudo que aparecesse de problemas eu talvez não conseguiria resolver (por falta de tempo hábil ou conhecimento). Então, sentei mais alguns dias (mesmo nem tendo esse tempo) e comecei a destrinchar todo esse modelo. Código a código, linha a linha de arquivo.
Porém, e voltando ao tópico anterior, tinha que usar um sistema de comentários que fosse, pelo menos temporariamente, utilizado de forma oficial no blog. Então, reativei uma instância do Commento - que atualmente só estava utilizando na página de comentários anônimos aqui - para todas as páginas do blog. Meu amigo Paulo, mestre dos CSS (entregues sem compromisso, rs) liberou um código customizado para um botão verdinho e o coloquei em produção no mesmo dia. Estava pronto, então, o sistema de comentários oficial. Hospedado em uma VM no plano sempre gratuito no Google Cloud Platform (usando 60MB de RAM do Compute Engine - aplicação e banco de dados = muito pouco!).
Depois de estudar e compreender de fato os erros que estavam dando, além de perguntas (na corda bamba da insistência, rs) ao próprio bigbyto aqui, consegui entender de fato como o processo agia, que basicamente foi projetado diferentemente do código original. A seguir, descrevo o passo a passo de implantação.
Vercel e a função de backend
Antes de começar com o backend, crie uma aplicação OAuth na sua conta do github, conforme o tutorial oficial do Gitalk. Isso garantirá que os comentadores possam fazer login na sua página de comentários.
Após isso, crie uma conta no Vercel. Esse serviço é, assim como outros, denominado serverless, que significa “sem servidor”. É uma forma de você executar uma aplicação (node.js, go…) sem precisar instanciar uma máquina virtual completa. A vantagem, claramente, é que o custo é bastante reduzido (pois a execução age sob demanda). Geralmente os serviços que oferecem esse recurso, como Cloudflare Workers, Netlify e o próprio Vercel têm opções gratuitas bem generosas.
Plano gratuito Vercel
O motivo disso é porque o código do bigbyto age de forma a retirar do frontend as credenciais da aplicação que você vai criar e que vai autorizar o login dos usuários na caixa de comentários. Essa é uma preocupação válida, já que expor credenciais no frontend quer dizer que qualquer um terá acesso a essa informação sensível, e de alguma forma poderá criar um hack para consumir indevidamente ou até quebrar sua aplicação. Cabe ressaltar que esse problema existe na ferramenta oficial Gitalk e simplesmente utilizá-la é aceitar essa condição. Remover significa utilizar um servidor intermediário que irá guardar essa informação, e este é o nosso backend (não há outra forma para isso). A mesma preocupação ocorreu com Krasimir, na postagem de anúncio do seu sistema de comentários baseados em issues Octomments. Utilizar as credenciais no próprio frontend é o preço a se pagar ao não utilizar um backend no Gitalk padrão.
Então, baixe esse código que bifurquei do próprio bigbyto e realize as suas modificações. O procedimento é relativamente simples:
1
git clone https://github.com/marlluslustosa/gitalk-anonmously-comment
Depois altere o arquivo config.js conforme suas necessidades. Deixo aqui um exemplo:
Os dados de appId, appSecret são encontrados na aplicação que você criou (conforme citado no primeiro parágrafo deste tópico) seguindo a documentação padrão do Gitalk. Como é mostrado na imagem abaixo, os dados sobre redirectURI e origin também são colocados lá.
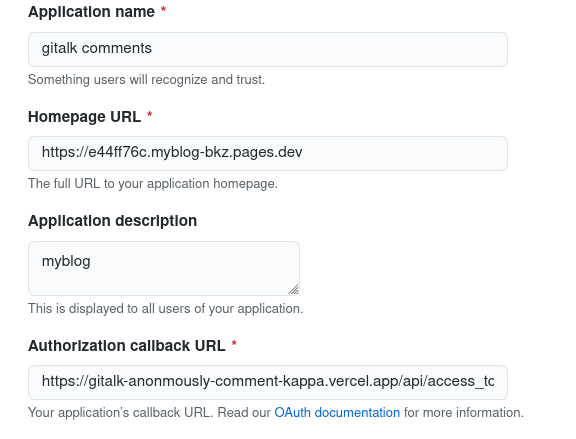
O accesToken é o Personal Access Token (PAT) do usuário que você vai criar para comentar anonimamente. Então, crie um novo usuário no Github para ser o alter ego externo anônimo (que irá colocar pra fora todos os anseios da sua comunidade). Aqui eu utilizei um PAT (fictício) da minha robô Araphen.
Quando você terminar a configuração da aplicação usando sua conta no Github, está pronto para subir o backend no Vercel, para em seguida adicionar o código no frontend (site).
Usando o Vercel CLI, após logar na conta (vercel login) só precisei usar o comando vercel --prod no diretório do repositório clonado (git clone...) localmente e o mesmo já realizou o build e deploy, me gerando após isso um subdomínio com final vercel.app (perceba o meu de teste acima foi https://gitalk-anonmously-comment-kappa.vercel.app ). Ele certamente gerará outro para você.
Frontend - código no blog
Na parte do frontend, o código é bem parecido com o original Gitalk, só que, como falei, você não vai preencher o ClientID nem ClientSecret, além disso, colocará o nome do usuário anônimo que iriá comentar na issue. No meu caso, foi a araphen. O código necessário para fazer funcionar é esse:
Na linha 10 você deverá colocar o repositório que armazenará as issues de comentários. No meu caso, coloquei este, descrito como gitalk_comments.
Utilizei a versão 1.6.8 do Gitalk pois foi a utilizada no código alterado pelo autor, então, baixei a pasta contendo o conteúdo do js e css dessa versão do frontend e adicionei em uma pasta no blog, conforme chamadas nas duas primeiras linhas.
O novo id, na linha 14, foi uma sugestão do bigbyto para resolver um problema que diz respeito ao tamanho do nome da label da issue (que tem um limite de 50 caracteres). Então, juntamente com a linha 6, que vai pegar os valores da url separados por /, a linha 14 vai pegar o último valor locationArr[locationArr.length - 1] , que sempre será no meu caso a descrição do post. Caso eu não tivesse colocado isso, neste link ele iria tentar colocar isso como label tecnologia/2016/02/17/importacaoexportacao-de-vms-no-xenserver-6-5, que ultrapassaria o limite de 50 caracteres, segundo documentação oficial. O resultado disso seria que quando alguém entrasse no post, o Gitalk iria procurar alguma issue que tivesse uma label igual à url (location.path) do blog. Então, iria dar um falso negativo e o sistema erroneamente iria relatar que não existe issue aberta. Essa modificação vale tanto para paths longos como curtos.
Agora é levantar o site para a produção que o mesmo carregará com a opção de comentários anônimos. No meu caso, subi em uma branch diferente da oficial e o cloudflare me gerou um domínio (deploy preview) para ele. Você pode acessar e testar comentários anônimos aqui.
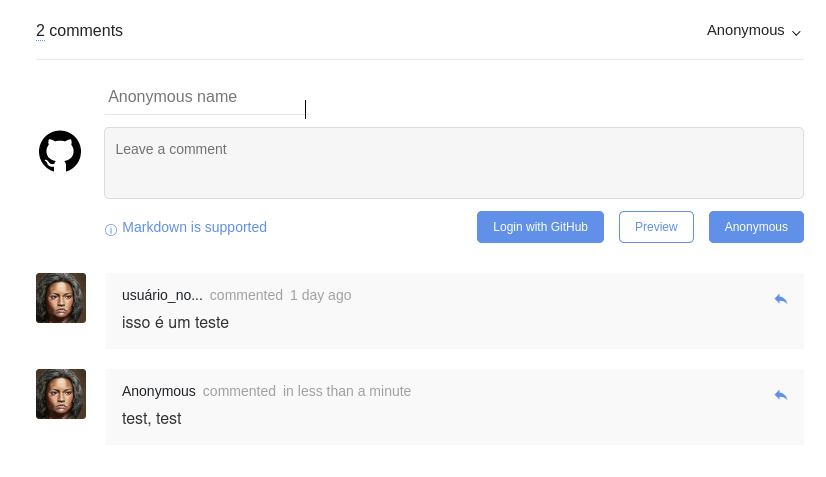
Alguns hacks para melhorias
Bem, a solução proposta tem um bug que vaza o token do usuário principal quando ele loga a primeira vez, quando não existe comentário no post. Esse login faz com que o Gitalk crie uma issue com a label do post e na descrição da URL logo em seguida o token.

Provavelmente seja no código do backend para escrita da issue que esteja vazando o token de acesso. Para resolver o problema, ou você o altera (coisa que por falta de tempo não deu pra resolver) ou cria manualmente uma issue com o label do post que acabar de publicar. Para tomar o processo automatizado, pode criar um workflow com Github Actions (como fiz aqui), no repositório onde armazena seu blog, que será disparado todas as vezes que um artigo for publicado. Esse workflow criará uma issue com o título do post, url e com as labels definidas para o Gitalk carregar o sistema pronto para receber comentários, anônimos ou não. Isso ainda trás uma possibilidade que pode vir a ser necessária, que é a de bloquear certos artigos de terem comentários. Caso o artigo não tenha nenhuma issue aberta com o padrão Gitalk, ele fornecerá a seguinte mensagem:

O Error: e is null é devido à variável de busca do id location no javascript ser nula, já que não existe issue referentes no repositório de comentários. Mais uma vez, para retirar esse erro, alguma modificação seria necessária no código do backend. Ele em nada afeta a execução do sistema, mas é um erro relacionado à mensagem logo em seguida (Related issues not found) e que poderia ser suprimido.
Outra opção de melhoria é a possibilidade de você não querer que usuários do github façam logins, ou seja, que só permita comentadores anônimos. Para fazer isso, basta alterar a url do RedirectURI (aquivo config.js) ou do Authorization callback URL, nas configurações da aplicação, para alguma inexistente ou tornando-as diferentes. Para o usuários conseguirem realizar login, as duas urls tem de estar iguais, para permitir a negociação de credenciais e autenticação. Se elas forem diferentes, a autenticação irá falhar, porém, a opção de comentários anônimos ainda permanecerá, já que não necessita desse procedimento. Esse método é denominado por mim de empata foda, rsrs. Uma gambiarrinha muito eficaz.
E o tal do SPAM? Bem, uma forma interessante para controle de SPAM e até mesmo flood, seria um workflow no repositório de comentários para verificar cada um, cada vez que ele surgisse. O disparo no Github Actions se quando uma label fosse adicionada ou issue comentada. A ideia era ter um script que iria verificar a existência de links ads, urls conhecidas em repositórios de hosts em blacklists (como esse) e removeria o comentário que batesse com alguma regra de bloqueio, bem como comentários repetidos nesse mesmo workflow. Também como opção para controle de flood, uma modificação no frontend como hCaptcha poderia diminuir a incidência de múltiplas requisições via scripts mal intencionados.
Agora chegou ao fim
Bem, era isso. O post acabou ficando mais longo do que imaginei, mas tratei de adicionar todos os meus percalços no processo. Isso certamente servirá como documentação para mim e a quem precisar. Em um futuro breve, caso ninguém tenha melhorado a estrutura, tentarei modificar e inserir as sugestões. Mas, com a explicação e o norte que eu dei, espero que algum usuário motivado resolva continuar a brincadeira!
Agradeço demais ao bigbyto pela ajuda e pelo tempo em relatar sua experiência em seu blog.
Tem alguma sugestão ou só quer desabafar? Comenta aí!